栏目分类
发布日期:2025-05-21 08:58 点击次数:120
昨日晚间,阿里巴巴集团公布新季度业绩,阿里云收入同比增长18%,达到301.27亿元,创下三年来的最快增速。其中最值得关注的一组数据是:AI相关产品收入连续第七个季度保持三位数的同比增长。
从我个人的角度,我更倾向于以AI公司的模式重估阿里的价值,因为它具有头部AI公司典型的“五力要素”,即分别具有:
——基础大模型的研发能力和研发团队
——反复拉锯战中抹平代差的高韧性
——亿级日活的toC应用作为试验场
——世界级领先的生态
——面向产业界的广泛落地
在我们考察的头部AI公司中,阿里不仅“五力”俱全,而且几乎都是长板,再加上极其具有规模效应和成本优势的云基础设施,我们似乎可以看到,“云+AI”的滚雪球式增长,将进一步推高“AI叙事”带来的价值重估,与未来更高的发展天花板。
——导语
01
无冕之王
评价一个企业的大模型竞争力,除了跑分屠榜以外,还应该看看它在实际中的市场影响力。
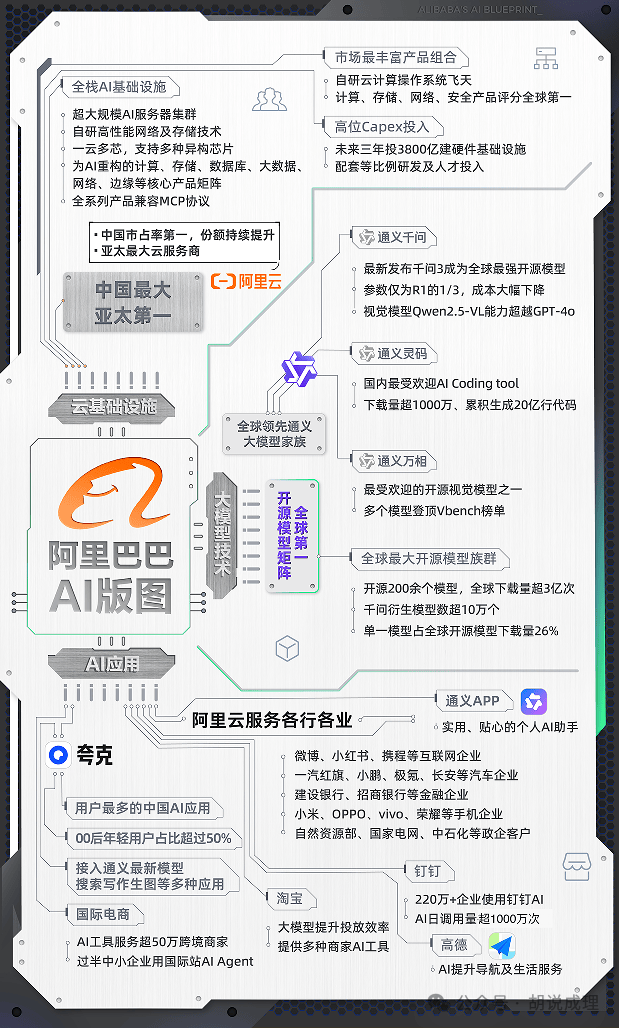
一组数据是,自2023年8月开源以来,通义千问的衍生模型数量已突破10万大关,将Meta的Llama系列远远甩在身后。而Qwen2.5-1.5B-Instruct模型更是达到26.6%的全球下载量占比,第二名LLama 3.1-8B仅占比6.44%。
另一组数据则是,截至2025年4月,阿里通义已开源200余个模型,全球下载量超过3亿次。
这不仅是数字意义上的优胜,某种程度来讲,这组数据更能说明阿里的AI业务已经在某种意义上成为全球AI的“无冕之王”。
这也从某种意义上证明,当年的开源选择是非常正确的决定。在彼时,开源派和闭源派可谓各执一词,讨论哪种模式更有助于企业的发展。而以上这些数据也说明,这一争议暂可告一段落。
在笔者看来,下载量和衍生模型数量,也可以看作另一种意义上的“市场占有率”,它可以反映某个模型得到市场认可、被二次开发和应用的实际情况。
大模型赛道仍在极早期,让用户“用起来”就赢在了起跑线上,这个朴素的道理谁都懂。但是,越是国际性、开放性的社区,就越依赖模型本身的特点和质量来赢得青睐,它很难采取类似于toC赛道的补贴、引流等策略,故而其反映出的规模和选择倾向,也更接近于全球AI开发者的真实选择。
并不是只有下游开发者才是通义的用户,高端玩家同样是——李飞飞团队以千问Qwen2.5-32B-Instruct开源模型为底座,训练出新模型s1,取得了与Open AI的o1和DeepSeek的R1等尖端推理模型数学及编码能力相当的效果;DeepSeek官方曾透露,其将DeepSeek-R1的推理能力蒸馏 6个模型开源给社区,这当中4个模型是基于Qwen-32B蒸馏的模型;伯克利Tiny Zero及上海交大LIMO也都在通义系列模型底座基础上激活其更强的推理性能。
在这个意义上,阿里不但是“无冕之王”,甚至在中美争夺全球AI第一创新策源地的反复拉锯中,极大的扩充了中国阵营的“站队”比例,它更体现的是这种国运级别的PK中,中国力量的崛起。

02
高韧性,抹平代际差异
被吴国打败后,勾践卧薪尝胆,暗中实施"十年生聚,十年教训"计划,不但主动引进强敌吴国的冶炼术以改良越国兵器,还推行"劝农桑"政策使国库收入增长300%,最终于公元前473年灭吴,成为春秋最后一位霸主。
大模型赛道亦如是,我们在“头部玩家”这一系列文章的“五力要素”中曾特别指出,大模型的竞争就是一个你追我赶,不断接受失败和总结创新的过程。它需要极高的韧性,在巨大的压力下反复抹平代价差异,最终在一个二十年级别的赛道中取得终局胜利。
DeepSeek横空出世的时候,曾经引发其它AI公司和相关概念股的大跌。于是,很多人就提出一个问题,如果一家百人规模的公司就可以搞出如此世界级的跨越式创新,那大厂们的巨额投资和庞大规模,是否意味着资源的错配和极大的浪费?
对于大模型赛道来说,有两种打法,平推式和跳跃式,DeepSeek就是典型的跳跃式,但跳跃式的出现是不可预估的。
说100来人的深度求索可以搞出划时代的产品,进而推论大厂的路径是高开销、低效益的,这恰恰不正确。对于大厂来说,重要的不是搞出一两款爆款模型(有当然更好),而是无论外部如何变化,一方面按自己的节奏推进,另一方面在业界前沿方向上进行研究和跟进,这是一个反复拉锯的过程,最终比拼的是耐心和韧性。
最鲜明的一个案例是,深度求索在1月20日同步推出了R1系列模型,一时间誉满天下;然后就在整整三个月之后的4月29日凌晨,阿里巴巴开源新一代通义千问模型Qwen3(简称千问3),参数量仅为DeepSeek-R1的1/3,成本大幅下降,性能全面超越R1、OpenAI-o1等全球顶尖模型,登顶全球最强开源模型。
什么叫抹平代际差异,这就是!如果要一定给出一个时限,那么应该是在90天以内。
比R1更进一步的是,千问3是国内首个“混合推理模型”,相当于把R1+V3融合在一起。千问3把“快思考”与“慢思考”集成进同一个模型,对简单需求可低算力“秒回”答案,对复杂问题可多步骤“深度思考”,大大节省算力消耗。
在模型的整体性能方面,千问3更是“强到飞起”——在奥数水平的AIME25测评中,千问3斩获81.5分,刷新开源纪录;在考察代码能力的LiveCodeBench评测中,千问3突破70分大关,表现甚至超过Grok3;在评估模型人类偏好对齐的ArenaHard测评中,千问3以95.6分超越OpenAI-o1及DeepSeek-R1。
这个成果浸透了阿里AI工程师们的汗水,但究其根本,之所以能够迎头赶上,是“五力要素”中的另一个能力——端到端的基础大模型研发能力。
一个几乎可以称为定理的观点是——企业的AI全栈能力最终决定响应速度,以千问3为例,因为拥有底层研发能力,可以没有限制条件的自主进行优化模型架构、训练策略和推理效率。
这种底层能力甚至要渗透到硬件层,通过软硬一体全栈优化,阿里云打造出一套全新的稳定高效的AI Infra,连续训练有效时长大于99%,模型算力利用率提升20%以上——同时也印证了一个道理——越有规模的企业并非越肆无忌惮的烧钱,而是利用规模优势做到更省。
前面我们提到了跳跃式进步,但大厂更多的是采取平推模式——不刻意追求单点突破,而是发挥规模优势和超级韧性,按照“你打你的,我打我的”的逻辑来操作。
总而言之,底气浑厚的大厂与做出跨越级创新的小厂,更多的是竞合多于竞争。如果说R1打开了深度推理这扇门,那它堪比发明了汽车的本茨;而阿里在其中的作用类似福特,福特是真正意义上的汽车工业之父,他并没有推翻本茨的优势,但洞察了本茨的劣势。并利用自己的流水线模式,将汽车的成本降到了一个非常低的水平,同时大幅度的提升了可靠性,最终成就了“每个人都买得起,用得起”的汽车产业之王。
回望千问3,其技术突破、成本优势、生态势能共同构成"马拉松式竞争"的三重推力,正如阿里CTO周靖人所言:"大模型不是算法单点突破,而是从芯片到框架的全栈战争”。
03
亿级应用,顶级玩家的标配
之前我们曾反复谈到过,一个头部玩家至少得有一个亿级用户规模的APP作为自家AI能力的试验场,阿里亦然。但有所不同的是,阿里不但在自己的主流业务场景如淘宝、钉钉中融入AI能力,更创造了依靠AI加持,创下最快打造全新亿级应用的记录之一。
作为一个长期观察搜索行业的业者,夸克在最初问世的时候,并没有得到我的太多看好。原因也很简单,谷歌、百度所代表的第三代基于超链分析的搜索已经非常成熟,市场集中度也非常高。搜索这个行业有个特点,就是在没有发生代际更替的情况下,后发者很难赶上领跑者。
除了在第三代搜索技术的框架内创新点已经不多之外,成本也是重要的考量——“全面”是衡量搜索引擎的核心指标,但“全面”也意味着需要向前追溯很多年,建立相应的索引库。但这件事对后发者是一件很难算过来账的事情——越是早期的索引,其被检索的概率就越低,而如果从当下做起往前去索引,其边际成本就会无限高,而效果则相当低。
但如果不做,又意味着在全面、相关度体验上很难超过头部搜索企业,这也是为何搜索行业的格局很难变动的原因——故此,当夸克问世时,我并不太看好这个产品。
但是在今年我开始对夸克刮目相看,今年1月15日,夸克升级品牌Slogan—“2亿人的AI全能助手”,亮出加速探索AI To C应用的全新业务态势,第三方数据显示,夸克用户规模持续保持高速增长,并领跑AI应用赛道,其中00后年轻用户占比超过一半。
如果单独PK搜索体验,夸克仍很难说就“超越”了传统搜索。但令人称许的是,夸克也没有停留在这一阶段,而是依赖AI的加持,走了一条差异化搜索的路径——夸克具备多模态和深度思考能力,不仅能处理简单的搜索任务,个性化指令也能轻松拿捏。
同时,在处理用户指令的过程中,随着“深度搜索”这样的差异化功能的上线,可以更为精准的从语义层面辨识用户的问题,实现了从“理解问了什么”到“理解并判断应该给用户什么样的答案”的飞跃;而在提供答案的过程中,夸克的深度搜索,也从“懂得要搜什么”、“懂得去哪里搜”和“懂得该怎么搜”。
这种与传统搜索“非对抗式竞争”的方法,让夸克得到了前所未有的增长,而其背后正是千问的不断进化——如我们前面提到的快思考和慢思考、优化调用算力、提升回复效率等,依靠的已经不完全是大力出奇迹,而真正意义上是一种体系性的演化。
和很多大厂“魔改”自己的经典产品相比,夸克从一个尝试性的业务,被明确为其成为阿里的AI旗级业务,真正发生质变的时间就在这一年甚至半年内。除了阿里在云服务、基础模型能力上有深厚的积累以外,我觉得阿里的一个思路是非常正确的,那就是给夸克定义为“让用户用最低的成本接触到AI的魅力”的toC导向。
在ChatGPT代表的生成式AI的能力逐渐成为行业主流后,大量的企业都试图让用户感受到大模型的魅力,但观察其产品路径,要么是无感的集成在原有的亿级应用中,用稳步渗透的方式改善用户体验,要么直接做成对话式的APP,给用户提供直接和模型对话的机会。
但从产品角度来讲,前者不容易被感知;后者的门槛则较高——除了重度知识工作者,一般用户打开这类应用的频次偏低……而夸克的聪明之处就在于,它“改良”了一个超高频应用——搜索,又针对的全都是传统搜索核心能力区之外的价值增量,这样在用户感知和用户活跃度上都有保证,这充分说明了阿里对于“AI就是要让用户去用”有深入的认知。
目前来看,阿里拥有的亿级日活产品可能是大厂里最多的,除了夸克还有钉钉、淘宝、通义等,这在大厂中也算是优势明显。
04
在产业化方向上做工
一个新的观察维度日益受到重视,那就是大模型在产业端的应用和落地情况。
几乎所有头部玩家都在这样几个方向上发力——代码、内容生成和智能体。
但千问3的打法不仅于此。
首先,千问善用、用足自己了的资源优势,以千问3为例,它同步推出的矩阵包含2款30B、235B的MoE模型,以及0.6B、1.7B、4B、8B、14B、32B等6款密集模型,每款模型均斩获同尺寸开源模型SOTA(最佳性能)。
这样的好处,是快速铺开应用面,如4B模型是手机端的绝佳尺寸;8B可在电脑和汽车端侧丝滑部署应用;32B最受企业大规模部署欢迎,有条件的开发者也可轻松上手……这种能力则非创业企业可以具备。
借助于不同尺寸的模型矩阵,千问3对手机、智能眼镜、智能驾驶、人形机器人等智能设备和场景的部署更为友好,所有企业都可免费下载和商用千问3系列模型,将大大加速AI大模型在终端上的应用落地。
当然,尺寸仅仅解决了部署问题,让应用跑起来的核心要素是成本——千问3在部署成本不到DeepSeek R1四成的情况下,性能全面超越国内领先模型。
而随着进一步拉低模型普及成本,高性能、高性价比的模型将加速中国AI应用的寒武纪大爆发。
当然,仅有推理模型是不够的,许多智能体以工具的形态出现,而有数据估算,一款百万级DAU的AI产品,倘若Agent化,消耗的tokens要翻30万倍。
对此, 千问3 在工具调用能力(function call)方面表现出色,在伯克利函数调用BFCL评测榜中,千问3创下70.76的新高,将大幅降低Agent调用工具的门槛。
在国际权威研究机构Omdia发布的《2025年度中国商用大模型》厂商评估报告中,阿里第二年获评领导者,通义大模型性能及商用能力蝉联中国第一。
各行各业正在加速接入通义系列大模型。近期,宝马宣布基于通义系列模型联合开发AI引擎,应用于中国市场的宝马新世代系列车型。目前,通义大模型已经服务了OPPO、vivo、荣耀、小鹏、蔚来、极氪、建行、招行、中国人寿、海尔、美的、创维、微博、携程、国家电网、数字重庆、中国科学院等大型企业和机构。
通义灵码成为中国最受欢迎的AI编程助手。目前,通义灵码插件下载量超1500万,累计生成超30亿行代码,服务上万家企业。
结语
一分耕耘 一分收获
多年以前,在云计算还是一个概念的时候,阿里就开始探索这一领域,期间遭遇过无数的挫折,但最终成为了亚太地区最顶尖的云计算服务商。
这也是第二代互联网巨头中,目前唯一一个稳定形成toC和toB双引擎驱动的企业。
当人们知道云计算是AI的摇篮和抓手的时候,阿里云已经在赛道上遥遥领先。阿里的“无冕之王”地位不是轻易得到的,阿里云AI是目前中国互联网公司里,在 AI 上投入最坚决、布局最全的。未来 3 年在 AI 上的 3800 亿资本开支史无前例,从基础设施、大模型、应用上都有完整布局,且阿里云和通义大模型家族都位列全球第一梯队。
我们不得不深思,如今的阿里,到底是一家互联网电商公司,还是一家AI企业?
